
Manufacturing processes are often described as deterministic systems governed by physics and chemistry. In practice, they are not.
A significant part of their variability comes from the people operating them. Different operators steer the same process in different ways. They apply different heuristics, react differently to similar situations, and follow practices that are often implicit rather than formalized. Even when procedures exist, they are interpreted and executed differently on the ground.
For machine learning models, this creates a fundamental challenge: the data is not generated by a single, consistent system. It is the result of multiple human strategies interacting with the same physical process.
As a result, the model is not learning one stable relationship between inputs and outputs. It is trying to learn across overlapping, and sometimes conflicting, patterns of operation.

Lack of Automation and Control Loops
In many manufacturing environments, processes are not fully automated. Control loops are either limited in scope or not implemented at all, leaving operators responsible for steering the system in real time.
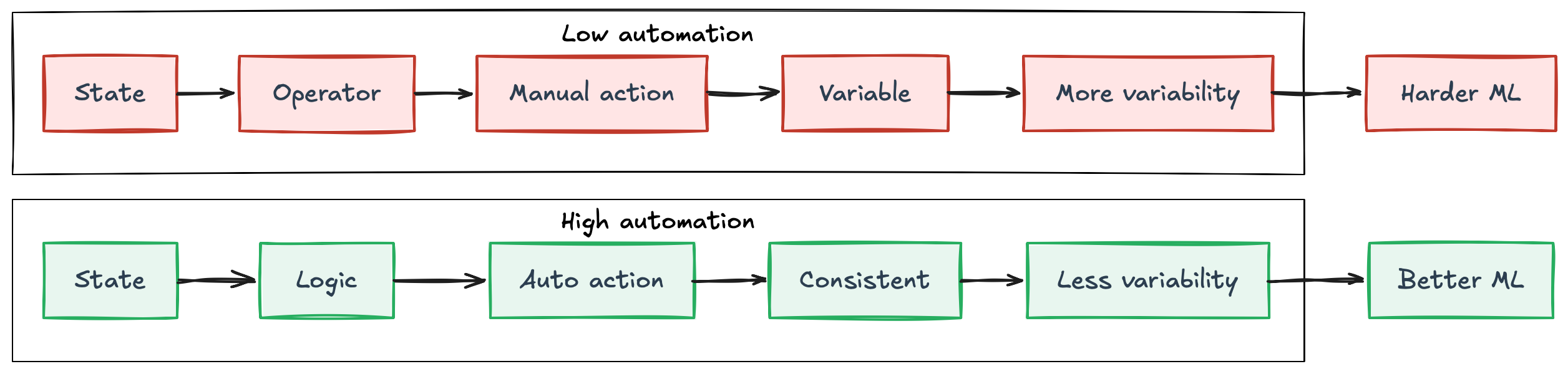
When this happens, the process is no longer governed by consistent control logic. It is governed by human decisions. Operators adjust setpoints, react to disturbances, and apply heuristics based on experience. These decisions may be effective locally, but they are rarely standardized. Different operators may respond differently to the same situation, introducing additional variability into the system.
In contrast, highly automated environments behave differently. Control systems enforce more consistent responses to similar conditions, reducing variability and stabilizing the process over time. This standardization makes relationships, trends, and correlations easier to detect.
For machine learning, this difference is critical. When the process is stable and governed by well-defined control loops, models can learn meaningful patterns with relatively modest amounts of data and compute. When it is not, the model is forced to learn across inconsistent behaviors, making generalization significantly harder.
This is why machine learning projects tend to be more successful in parts of the plant that are already advanced in terms of automation. Automation does not just improve operations, it creates better conditions for data-driven methods to work effectively.
Not Impossible, But a Much Harder Learning Problem
From a machine learning perspective, one could argue that operator variability should not be a fundamental problem. If every operator action affects the process, and if that effect is reflected in the data, then the model should be able to learn the relationship between observed inputs and outcomes.
Technically, this is true. Machine learning models are designed to approximate complex functions. If the dataset contains enough examples of different operating conditions, operator strategies, process disturbances, and resulting outcomes, the model can learn useful patterns.
The problem is not that learning is impossible. The problem is that human-driven variability increases the complexity of the function the model has to approximate.
In a highly automated process, the same situation tends to generate a similar response. The control logic is standardized, making the relationship between inputs and outputs more stable. In a manually steered process, the same situation can be handled differently depending on the operator, the shift, the production objective, the level of experience, or informal practices used on the ground.
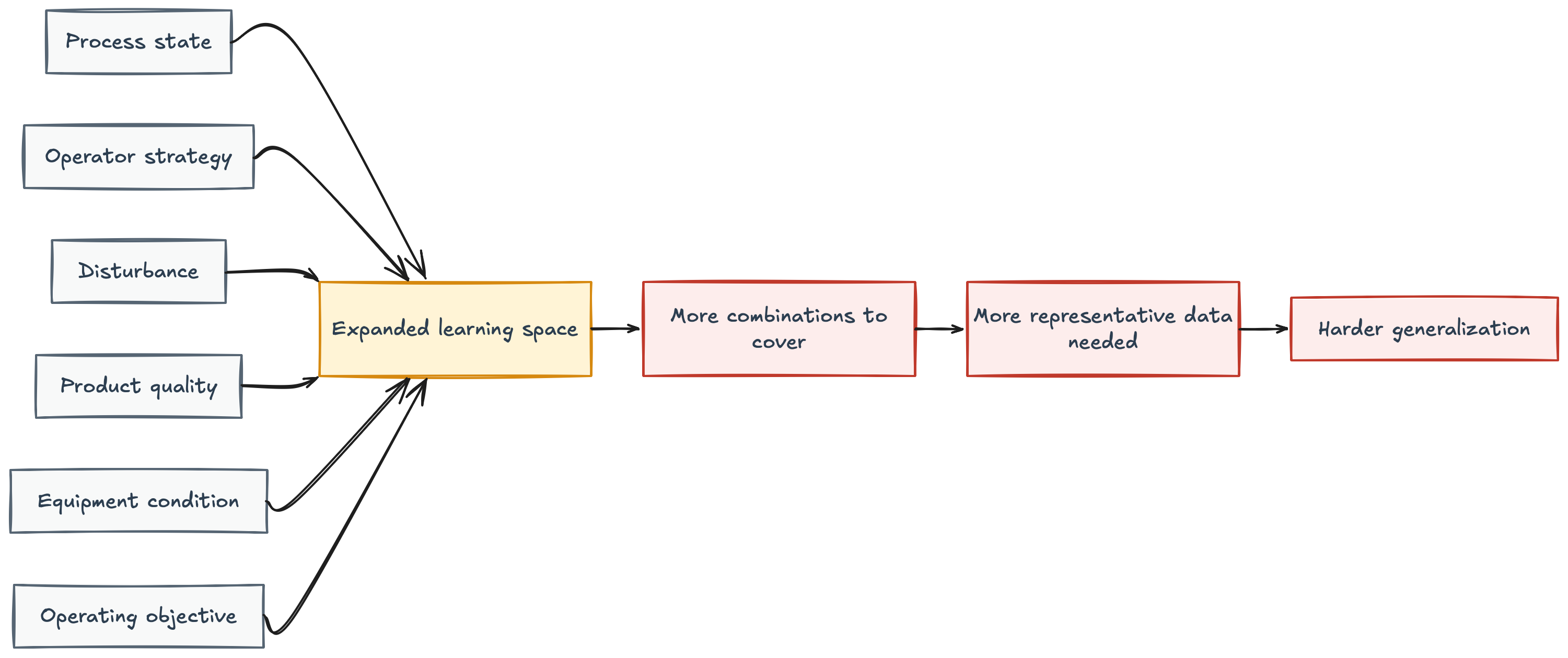
This means the model is not only learning the behavior of the physical process. It is also learning the different ways humans interact with and control that process. This expands the learning space.
The model now needs enough representative examples for each relevant combination of conditions: process state, operator strategy, disturbance, product quality, equipment condition, and operating objective. In practice, industrial datasets are often large in volume but sparse in coverage. They contain many data points, but not necessarily enough examples of each meaningful situation.
This is why a model may perform well during testing and still fail in production. It may have learned patterns that were valid for the dominant operating behavior in the historical data, but not for less frequent strategies, rare disturbances, or new ways of steering the process.
The issue is therefore not whether machine learning can learn the effect of operator behavior. It can. The issue is whether the available data covers that behavior well enough for the model to generalize reliably.
Use a Recommender System to Reduce Operator-Driven Variability
If human-driven variability makes the learning problem harder, then one practical objective should be to reduce this variability before asking ML models to learn from it.
Automation is one way to do that. But in many manufacturing environments, the control problem is too complex to be handled immediately by simple PID loops. It may involve long delays, multiple interacting variables, changing operating conditions, and trade-offs between stability, quality, throughput, and energy consumption.
In these cases, advanced process control may be required. But implementing APC is not always immediate. It requires reliable measurements, clear objectives, and enough confidence in how actions affect future behavior.
This is where a recommender system for process control can be useful. The objective is not to replace automation or directly predict the optimal action. The objective is more pragmatic: reduce operator-driven variability by promoting the best historical ways of steering the process.
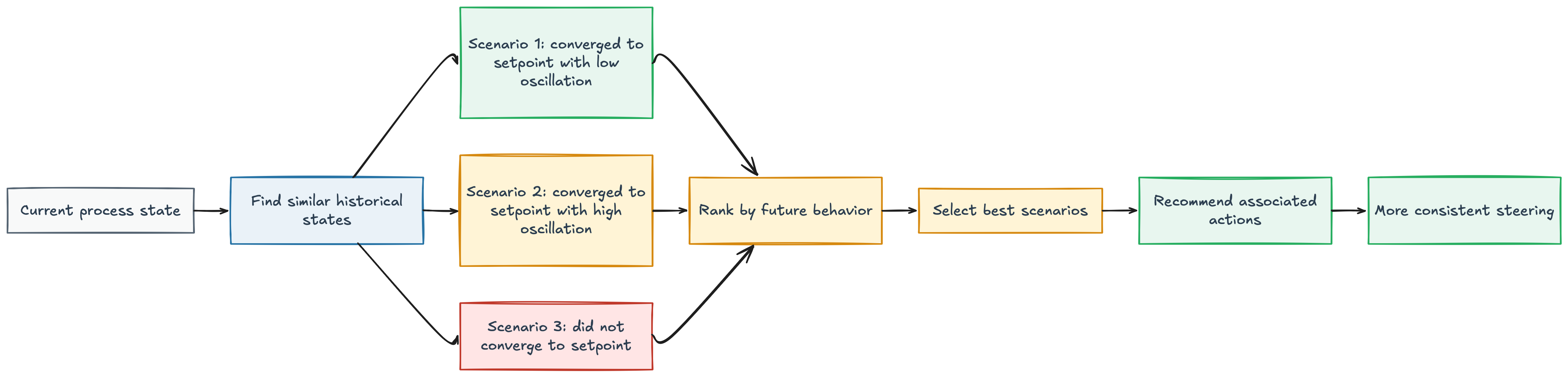
One approach that showed promising results in my experience was to decompose the process into its theoretical control loops, even if those loops were not yet automated in practice. For each loop, we identified the relevant process state, the target setpoint, and the actions that could influence convergence toward that setpoint.
At each moment, we searched the historical data for past situations that were similar to the current state. This similarity was calculated within the context of the specific control loop, using the variables that matter for that part of the process. This gave us a set of historical scenarios comparable to the current situation.
The next step was to evaluate what happened after each scenario. Did the process converge toward the setpoint? Did it remain stable around it? Did it avoid large oscillations or unnecessary corrections?
Among the similar historical situations, we selected the ones that produced the best future behavior. The actions taken in those situations were then recommended to the operator.
In this sense, the system behaves less like a classical predictive model and more like a recommender system for industrial operation. It does not try to invent a control strategy from scratch. It retrieves similar historical process states, evaluates which ones led to the best outcomes, and recommends the actions associated with those successful scenarios.
This makes the recommendation operationally understandable:
“We have seen similar situations before, and these are the actions that led to the best convergence, stability, or process behavior.”
This approach capitalizes on the knowledge already present in the plant. Instead of depending only on the operator currently in charge, it makes the best observed steering practices available across shifts and teams.
More importantly, it connects directly to the core challenge discussed earlier. By promoting more consistent actions in similar situations, the recommender system helps reduce the variability introduced by different operator strategies.
This can act as a bridge toward ML-based APC. Before expecting an ML model to learn a complex control strategy, the plant first becomes more standardized. The process becomes more consistent. The learning space becomes smaller.
As a result, future ML models have better conditions to learn stable relationships and generalize reliably.
ML Should Build on Industrial Fundamentals
Industries should not be driven by machine learning hype. ML can bring value to manufacturing, but only when the process is ready for it.
Before chasing complex models, the basics should be in place: reliable measurements, stable operation, clear objectives, and enough control maturity.
In many cases, these fundamentals may create more value than ML itself. Machine learning should not be used to compensate for a poorly controlled process. It should be applied where it can build on a solid industrial foundation.
Before looking for marginal gains with ML, make sure the fundamentals are not where the real value still exists.